
A data quality framework is the architectural plan for your company's most critical asset: its data. It’s a blueprint that brings together your people, processes, technology, and governance to make sure every piece of information is reliable, accurate, and ready for action.
Think of it as the system that ensures you can trust your data to support confident, clear-headed decisions.
What Is a Data Quality Framework and Why It Matters
Imagine trying to build a high-rise skyscraper without a blueprint. The foundation would be questionable, the wiring a tangled mess, and the final structure dangerously unstable. You wouldn’t risk it. Yet, countless businesses run their operations on data that lacks any structural integrity at all.
A data quality framework is that essential blueprint for your data. It’s not a rigid set of rules you check off a list; it’s a living system designed to manage, measure, and improve the health of your information from the moment it’s created to the moment it’s used.
Without this structure, you’re operating on shaky ground. Decisions are based on flawed insights, marketing campaigns miss their mark, and financial forecasts become little more than expensive guesswork. This is where the true cost of bad data becomes painfully clear.
The Domino Effect of Bad Data
The consequences of ignoring data quality aren't just theoretical—they hit your bottom line, hard. Studies have shown poor data quality can cost a single organization an average of $15 million annually.
These costs don't appear as a single line item. They bleed out across the business in subtle but damaging ways:
- Wasted Hours: Your team spends valuable time hunting for correct information, fixing errors, and double-checking reports instead of focusing on high-value work.
- Failed Initiatives: You invest heavily in AI or analytics, only for the models to produce garbage results because they were trained on flawed data.
- Eroding Customer Trust: Inaccurate customer records lead to billing mistakes, shipping errors, and tone-deaf marketing that directly damages your brand's reputation and customer loyalty.
The Four Pillars of a Data Quality Framework
A strong data quality framework stands on four interconnected pillars. Each plays a distinct role, but they all work together to build a culture where data is treated as a strategic asset.
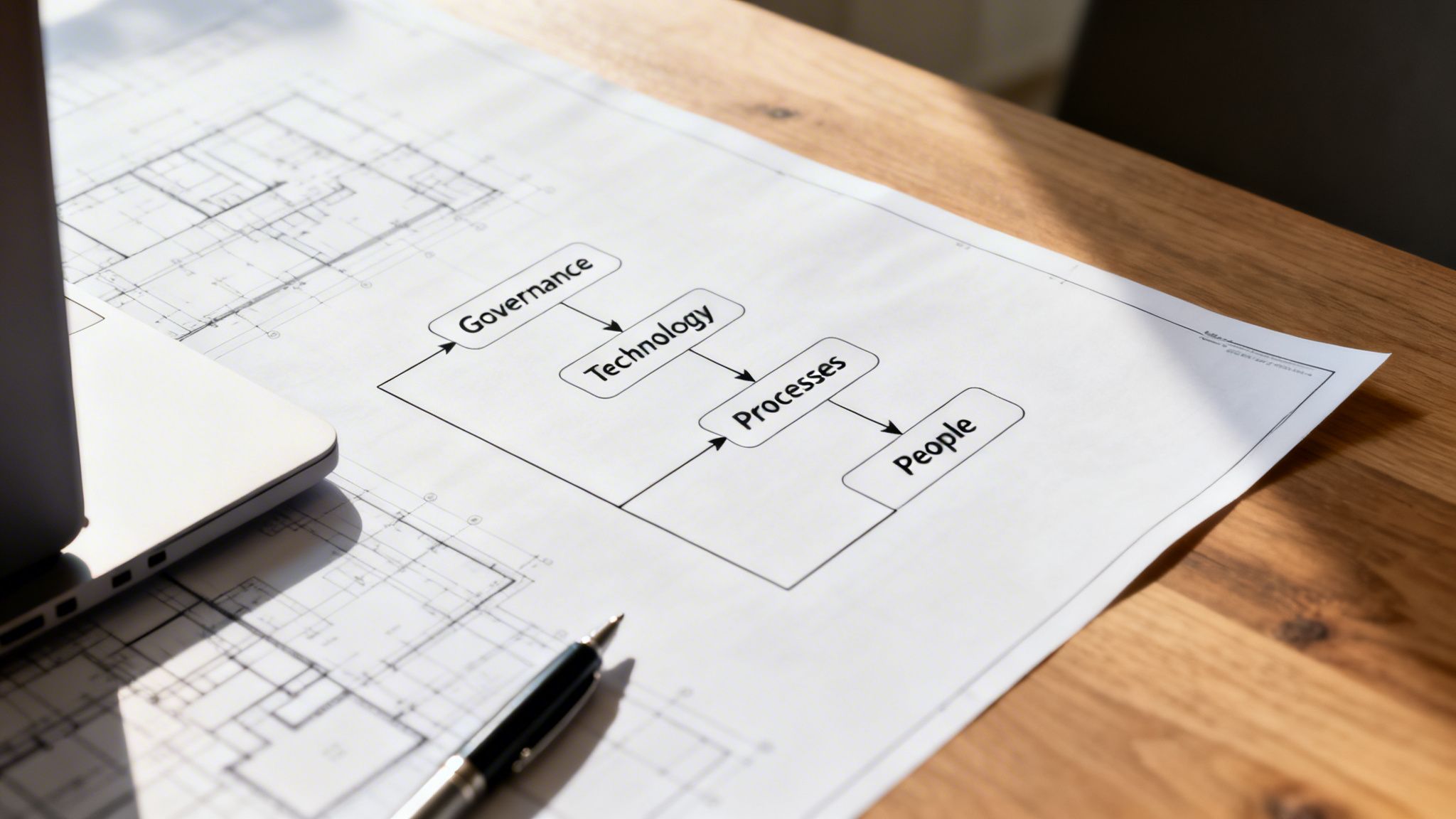
This table breaks down how each pillar contributes to a healthier, more reliable data ecosystem.
The Four Pillars of a Data Quality Framework
| Pillar | Core Function | Business Outcome |
|---|---|---|
| People | Assigns roles and builds a data-aware culture. | Ownership and accountability are clear, and everyone understands their role in maintaining data integrity. |
| Governance | Sets the rules, policies, and standards for data. | Decisions about data are consistent, compliant, and aligned with business goals. |
| Processes | Defines the workflows for creating, managing, and using data. | Data moves through the organization efficiently, with quality checks embedded at every stage. |
| Technology | Provides the tools for profiling, cleansing, and monitoring data. | Data quality tasks are automated and scalable, freeing up human expertise for strategic work. |
Together, these pillars create a self-reinforcing system that continuously improves the trustworthiness of your information.
The idea of standardizing data quality isn't new. Back in the 1990s, the International Monetary Fund (IMF) developed its Data Quality Assessment Framework (DQAF) to ensure global macroeconomic statistics were reliable. This model proved so effective it was adopted in over 100 countries.
Today, businesses that adopt similar principles for their IT and BPO services see significant returns. By embedding rigorous governance early in their data pipelines for cloud, AI, and finance operations, companies have reported efficiency gains of 25-30% in their decision-making.
A data quality framework transforms data from a potential liability into a strategic asset. It's the disciplined practice of ensuring information is not just collected, but cared for, so it can be trusted to drive growth and innovation.
Understanding these pillars is the first step. To dig deeper into how these concepts are applied in practice, exploring different Data Quality Frameworks can offer valuable real-world examples. By building a strong framework, you’re not just cleaning data; you’re building a more resilient and competitive organization.
As you continue this journey, you may also want to assess where your organization stands today by using a data maturity model.
Engaging a US-based outsourcing partner can significantly accelerate this process, providing access to specialized expertise without the overhead of building an in-house team from scratch. For a consultation on how we can help, call (310) 800-1398 / (949) 861-1804 or email [email protected].
The Six Dimensions of High-Quality Data
Before you can build a solid data quality framework, you first have to agree on what “good” data actually looks like. This isn’t some abstract, academic exercise. It’s about understanding the specific traits that make information trustworthy enough to bet your business on.
We call these traits the six dimensions of data quality.
Think of them like the vital signs of your data’s health. Just as a doctor checks multiple vitals to assess a patient, you need to check these six dimensions to know if your data is fit for duty. Ignoring one can be just as dangerous as having them all in bad shape.

Accuracy and Completeness
Accuracy is the one everyone gets intuitively. Does the data reflect reality? If your CRM says a customer lives at 123 Main Street, but they moved out five years ago, that data is inaccurate. Every piece of mail you send there is money down the drain.
Right alongside accuracy is completeness. This asks if you have all the information you need. Imagine a new lead in your system. You have their name and company, but no email, no phone number, and no industry. That record isn't just incomplete; it's useless for your sales team.
Incomplete customer profiles are a primary culprit behind failed marketing campaigns. You can’t personalize outreach or build meaningful segments when you're working with half the story.
Consistency and Timeliness
Consistency is all about uniformity. Is a product’s price listed as $49.99 on your website, $49.99 in your inventory system, and $49.99 in the latest marketing email? If not, you have an inconsistency problem.
This isn’t a minor clerical issue. It’s the root of pricing disputes, angry customer service calls, and a steady erosion of brand trust. It creates operational chaos.
Timeliness, meanwhile, measures whether data is available when it matters. A report on last quarter’s sales figures is interesting. That same report, delivered the day after the quarter closes, is powerful. Stale data forces you to be reactive, making decisions based on where you were instead of where you need to go.
The dimensions of data quality are all interconnected. Focusing on accuracy while ignoring timeliness is like receiving a perfect, detailed map of a city a week after you’ve already left. High-quality data must be strong across all dimensions, not just one.
Validity and Uniqueness
Validity is about whether your data follows the rules. Does an email address look like an email address ([email protected])? Is a date of birth a real date? Invalid data is a red flag, often pointing to a broken data entry form or a flawed system integration. It can stop automated workflows dead in their tracks.
Finally, uniqueness ensures you don't have multiples of the same record. Duplicate customer profiles are the classic example. They bloat your customer count, make it impossible to see a single customer's full purchase history, and lead to embarrassing moments, like sending the same person the same "Welcome!" email three times. It screams unprofessionalism.
To truly build an effective data quality framework, you must get your arms around all six of these dimensions. It requires a shift in thinking, much like understanding the difference between designing a system and actually implementing it. In the quality world, this means distinguishing between the proactive processes you build and the reactive checks you perform. For a deeper dive into these foundational concepts, it's worth exploring resources on quality assurance vs quality control.
Mastering these dimensions isn't a one-off project; it's a continuous commitment. It demands clear governance, the right tools, and well-defined processes. For businesses wanting to accelerate this journey, partnering with a US-based outsourcing expert can provide the specialized skills to build and maintain a robust framework without the heavy internal lift. To see how we can help, call us at (310) 800-1398 / (949) 861-1804 or email [email protected].
Building Your Data Governance Dream Team
A data quality framework is only as good as the people who bring it to life. You can have the best technology and the most elegant processes, but without clear ownership, they’re just expensive shelfware. This is where data governance—the human side of the equation—comes in. It’s about putting a team on the field to uphold standards, fix problems, and build a culture where everyone feels responsible for data quality.
Think of it like a city’s water supply. You have civil engineers who design the system (data architects), maintenance crews who find and fix leaks (data stewards), and city planners who decide where new pipelines should go (data owners). Each role is different, but they all work together to make sure clean, reliable water flows to every home. Your data deserves the same kind of coordinated care.

Defining Your Key Data Roles
You don’t need to build a massive bureaucracy overnight. A practical governance model starts by defining a few core roles. When everyone knows who’s responsible for what, things just work better.
Data Owners: These are senior business leaders, like the VP of Sales who "owns" all customer data. They are strategically accountable for the data in their domain—its security, its ethical use, and how it drives business goals. They aren’t in the weeds of daily data management, but they have the final say on access and policy.
Data Stewards: These are your hands-on data champions. As subject matter experts, they are embedded in the business and responsible for the day-to-day quality of specific data sets. They’re the ones defining quality rules, investigating oddities, and fixing data-related issues. They are the go-to people.
Data Custodians: This role usually falls to your IT team or data engineers. They manage the technical infrastructure where the data lives—the databases, pipelines, and security systems. While the Data Owner decides who can see the data, the Data Custodian is the one who actually implements and enforces those permissions.
This simple division of labor ensures that business strategy, tactical management, and technical execution are all covered.
The Data Quality Council and Escalation Paths
What happens when a data problem crosses departmental lines? Without a clear structure, you get finger-pointing and gridlock. That’s why successful organizations create a Data Quality Council. This is a cross-functional committee, usually made up of Data Owners and other key leaders, that acts as the steering committee for your entire framework.
The council's job is to set high-level data strategy, mediate disputes between departments, and champion the importance of data quality across the organization. It provides the leadership needed to turn a governance policy into a living, breathing practice.
Just as critical are clear escalation paths. When a Data Steward finds a major error, they need a documented process to get it fixed. This ensures problems are addressed by the right people, fast, instead of getting lost in an email chain. A typical path might look like: Data Steward -> Data Owner -> Data Quality Council.
A well-oiled governance model is your best defense against internal chaos and external threats. For instance, market research and BPO firms are increasingly battling data fraud. A strong framework helps fight this by embedding fraud detection into daily work: stewards manage the operational checks, custodians automate security in the data pipelines, and a central council sets the anti-fraud strategy. This structure is also essential for complying with regulations like GDPR, where fines for negligence have been massive. You can find more on how these frameworks dismantle data silos in this detailed analysis from EMI Research.
Putting this team together from scratch is a serious undertaking. It’s why many companies choose to partner with a US-based outsourcing firm. An expert partner gives you immediate access to seasoned data governance professionals who can stand up these roles and processes efficiently, putting you on the fast track to trustworthy data. For a consultation on building your governance team, call us at (310) 800-1398 / (949) 861-1804 or email [email protected]. You can also learn more about how a dedicated data governance consultant can accelerate your success.
Choosing the Right Tools and Architecture
Once you’ve rallied your governance team and set your quality standards, the conversation naturally shifts from what to how. This is where technology comes in. A strong data quality framework isn't just a set of rules on paper; it's brought to life by a tech stack that can profile, clean, and monitor your data as it flows through the business. The goal isn’t to collect shiny new tools, but to choose the right ones that plug seamlessly into your existing architecture and solve your most pressing problems.
Think of your data architecture—whether it's a traditional ETL pipeline, a sprawling data lake, or a modern cloud warehouse—as a factory assembly line. Your data quality tools are the specialized machines and quality control stations you install along that line. Some are for initial inspection (profiling), others are for repairs (cleansing), and the most advanced ones provide continuous surveillance (observability).
Key Categories of Data Quality Tools
The market for data quality tools can be a crowded and noisy place. The good news is that most solutions fall into a few distinct categories. Understanding them helps you assemble a tech stack where every piece has a clear job to do.
- Data Profiling and Validation: These are your inspectors. They’re the first line of defense, scanning your data sources to give you a quick, honest assessment of your data’s health. They spot the obvious problems—like null values, mismatched formats, and broken relationships—before they go any further.
- Data Cleansing and Enrichment: When profiling tools find a mess, cleansing tools help you clean it up. They’re the repair crew, standardizing formats, correcting typos, and merging duplicate records. Enrichment tools take it a step further, filling in the gaps by adding valuable context from external sources.
- Data Observability Platforms: This is the modern, proactive approach. Instead of just running scheduled checks for problems you already know about, these platforms act like a 24/7 security system for your data pipelines. They use AI to constantly monitor for "unknown unknowns"—like sudden drops in data freshness, unexpected changes in schema, or unusual volume spikes—and alert you before they wreak havoc downstream.
The right mix really depends on where you are in your journey. A small startup might get by with a few simple validation scripts, while a large enterprise will need a fully automated, end-to-end observability platform to manage its complex cloud environment.
Integrating Tools into Your Architecture
The most powerful tools aren't the ones that sit on a shelf; they're the ones that integrate directly into your daily data workflows. This is absolutely critical. You want to catch errors at the source, not after they’ve already corrupted your financial reports or derailed your machine learning models.
Your data quality tools should act as automated gatekeepers within your data pipelines. By embedding checks directly into your ETL or ELT processes, you shift from reactive cleanup to proactive prevention, building quality in from the start.
For example, you can configure a validation tool to run automatically every time a new batch of data hits your warehouse. If that data fails a critical test—say, a sudden 25% spike in incomplete customer records—the pipeline can be paused instantly. An alert goes out, the issue gets fixed, and disaster is averted before bad data ever reaches your analysts.
This proactive mindset is everything. Since the early days of frameworks like the IMF's DQAF, the entire field has moved toward automation and prevention, with modern standards like ISO 8000 certifying data integrity. Research shows that poor data quality sinks around 23% of analytics projects, but by automating rules within the ETL process, you can catch 85% of issues before they become real problems, driving massive annual improvements.
The Advantage of a US-Based Outsourcing Partner
Choosing, implementing, and integrating these tools requires deep, specialized expertise. This is where leaning on a US-based outsourcing partner can give you a powerful advantage. Instead of pulling your own team off critical projects for a long and expensive tool evaluation process, you can tap into a team that has already been there and done that across dozens of industries.
An expert partner can quickly assess your architecture, recommend the most cost-effective toolset for your specific needs, and manage the entire integration from start to finish. This doesn’t just get you to reliable data faster; it frees up your internal team to do what they do best—focus on your core business. Whether you need to set up a simple validation workflow or deploy a sophisticated observability platform, bringing in an external team is often the quickest and most efficient path forward.
To discuss how we can help you select and implement the right tools for your data quality framework, call us at (310) 800-1398 / (949) 861-1804 or email [email protected]. You can also learn more about our comprehensive data analytics services.
Your Practical Roadmap to Putting the Framework Into Action
Theory is one thing, but execution is where the real work begins. You've got your governance team lined up, your quality dimensions defined, and your tech stack in mind. Now, it's time to bring your data quality framework to life.
The biggest mistake companies make is trying to boil the ocean—attempting to fix everything, everywhere, all at once. The most successful rollouts do the opposite. They start small, prove their value in one corner of the business, and use that win to build momentum.
Think of it like launching a new product. You wouldn't build the final, feature-complete version and push it to your entire customer base on day one. You’d start with a Minimum Viable Product (MVP) to test your assumptions and show that you're on the right track. For us, that MVP is a high-impact pilot project.

Stage 1: Launch a High-Impact Pilot
The first step is picking the right pilot project. This can't be a random choice. You need to find a business process where bad data is causing obvious, visible pain—and where a fix will deliver a clear, undeniable win.
A classic example is the "customer master" dataset. When this data is a mess, the pain is felt across the company. Sales outreach sputters, marketing campaigns miss their mark, and customer service struggles. Cleaning this up provides a powerful, tangible business case that no one can argue with.
Once you’ve found your target, it's time to execute.
Assess and Set Goals: First, you need a baseline. Profile the target dataset to see just how bad things are. What’s the current error rate for completeness? How many duplicate records do you have? Then, set a concrete goal, like: "Reduce duplicate customer records by 90% in the next quarter."
Get Executive Buy-In: Use your baseline assessment to build your business case. Don’t talk about "clean data"; talk about business outcomes. Show the executive team exactly how much money is being wasted on returned mail because of bad addresses, or how many sales leads are dead on arrival due to incomplete contact info.
Assemble the Pilot Team: You don't need a huge committee. Start with a committed Data Owner (like the VP of Sales), a hands-on Data Steward (maybe a top sales ops manager), and a Data Custodian from the IT department to handle the technical side.
Stage 2: Implement and Measure
With your pilot defined, it’s time to get to work. This is where your chosen tools and the business rules you’ve defined finally come off the page and get applied to real data. The pilot team will start cleansing existing errors and, just as importantly, set up the guardrails to prevent new ones from getting in.
Throughout this entire stage, measurement is everything. You have to track your progress against the baseline you established in stage one.
The goal of a pilot isn’t just to clean data; it’s to generate evidence. A dashboard showing a steady drop in data errors—alongside a clear improvement in a business KPI like marketing bounce rates—is the single most powerful tool you have for winning hearts and minds.
Stage 3: Scale Across the Organization
A successful pilot gives you two critical things: a proven blueprint for success and a rock-solid business case to expand your efforts. The final step is to build a broader rollout plan, identifying the next set of critical data domains and repeating the process.
But this is where many organizations hit a wall. Managing a full-scale data quality program in-house is a massive undertaking. It demands a set of specialized skills that are difficult to find and expensive to hire.
This is where a US-based outsourcing partner can give you a huge advantage. An expert partner brings a team with proven methodologies, ready to execute your roadmap efficiently from day one. By outsourcing the implementation, you get immediate access to top-tier data engineers and governance specialists without the long hiring cycles or the strain on your internal teams. It’s the fastest way to get to trustworthy data, freeing up your people to focus on what they do best.
To learn how an expert partner can drive your implementation roadmap, call us at (310) 800-1398 / (949) 861-1804 or email [email protected].
The Smartest Shortcut: Partnering with a US-Based Data Quality Team
Building a truly effective data quality framework from scratch is a massive undertaking. It’s not something you can assign to a junior analyst or an already-overloaded IT team. It demands a rare combination of talent: data governance strategists, battle-hardened data engineers, and sharp analysts who can connect the technical dots back to real business problems.
For most companies, trying to recruit, hire, and train this kind of specialized team in-house is a long, expensive, and often frustrating journey. You spend months searching for the right people, and even then, it takes years to build the internal knowledge and refined processes that actually deliver results.
This is where a strategic US-based outsourcing partner becomes less of a vendor and more of an accelerator. Instead of starting from zero, you get to plug into a team that has already been down this road dozens of time across different industries. It’s like skipping the years of trial and error and jumping straight to a proven, working system.
Why a US-Based Partner Gives You an Edge
Partnering with a firm like NineArchs offers a different kind of value than just filling seats. You’re bringing on a partner who works when you work, breathes the same market air you do, and operates under the same high standards for security and data privacy.
This alignment is critical. It erases the friction that so often plagues global outsourcing—no more 3 AM calls, no more cultural misunderstandings, and no more wrestling with different compliance norms. Communication is just smoother, and projects move faster.
The benefits become clear almost immediately:
- Smarter Economics: You sidestep the enormous overhead of recruiting, salaries, benefits, and training for a full-time team. Instead, a large capital investment becomes a predictable, manageable operational cost, giving you access to world-class talent on your terms.
- Scale at Will: Your data needs aren't static; they ebb and flow with business projects and priorities. An expert partner lets you instantly scale your data quality team up for a new initiative or down when a project is complete, all without the HR headaches of hiring and firing.
- Instant Access to Pro-Grade Tools: Leading data partners come prepared. They bring their own licenses for sophisticated data profiling, cleansing, and observability platforms. This means you get the benefit of enterprise-level technology from day one, without the six-figure price tag.
The real power here is freeing up your best people. By outsourcing the foundational work of building and maintaining your data quality, you allow your internal teams to do what they were hired to do: focus on innovation and driving the business forward. You get the confidence of a rock-solid data foundation without distracting your team from their core mission.
For a CTO, this is the most intelligent way to augment their team and hit critical data milestones on time. For a CFO, it’s the most direct route to getting the kind of reliable, trustworthy numbers needed to steer the company with confidence.
A US-based partner isn’t just another vendor on your invoice. They become a genuine extension of your team, dedicated to one thing: accelerating your path to data you can actually trust.
Ready to build a world-class data quality framework without the in-house headache? Let's talk about how a dedicated US-based partner can turn your data into your most valuable asset. Call (310) 800-1398 / (949) 861-1804 or email [email protected].
Frequently Asked Questions About Data Quality Frameworks
Whenever you start a big project like building a data quality framework, the same questions always pop up. They’re the ones that keep leaders up at night, wondering if they’re on the right track or if the investment will truly pay off.
Getting clear, confident answers is the key to moving forward without hesitation. Let's tackle some of the most common questions we hear from leaders just like you.
How Do We Measure the ROI of Our Data Quality Efforts?
Thinking about the ROI of data quality purely in terms of cost savings is a mistake. Yes, you’ll absolutely save money—less cash wasted on returned mail, fewer hours spent by your team fixing broken reports. But that's only half the story. The real value comes from what you gain, not just what you save.
The best way to see it is as a two-sided coin. On one side, you have cost reduction. This is where you track the decline in customer complaints about billing errors, or the drop in manual data entry corrections. On the other, you have revenue generation. This is the uplift you see in marketing campaigns when your lead lists are clean, or the rise in sales conversions because your team finally has complete, trustworthy customer profiles.
The most powerful business case you can make will always combine defense with offense. For example: "By cleansing our customer data, we saved $50,000 in wasted marketing spend and, more importantly, increased lead conversion rates by 15%, which added an estimated $200,000 to our new business pipeline."
What Are the First Steps a Small Business Should Take?
For a small or medium-sized business, the thought of a "full-scale data quality framework" can feel like being asked to boil the ocean. It’s intimidating. The secret is to ignore the grand vision for a moment and start with a single, high-impact win.
Here’s how you get started:
- Find the Obvious Pain: Where does bad data hurt the most? Is it your messy customer list that’s killing your marketing outreach? Your product inventory data causing shipping nightmares? Pick that one.
- Give It a Clear Owner: Nominate a business leader to be the Data Owner—the person whose neck is on the line for that data's success. Then, find a subject matter expert to be the Data Steward, the hands-on person who knows it inside and out.
- Define "Good" in Simple Terms: Don’t write a novel. Just agree on a few basic rules. For a customer list, it might be as simple as, "Every new record must have a valid email and phone number. No exceptions."
- Clean It and Guard the Gate: Roll up your sleeves and clean the existing data to meet your new rules. Then, put a simple process in place to check all new data as it arrives.
This focused approach gives you a quick, tangible victory. It proves the value and builds the momentum you need to justify expanding the effort.
How Does Data Quality Support AI and Machine Learning?
Think of it this way: AI is a brilliant, powerful engine, but data is its fuel. If you pour dirty, contaminated fuel into that engine, you’re not going to get high performance. You’re going to get sputtering, breakdowns, and unreliable results.
An AI model is only as smart as the data it learns from. Feed it flawed, incomplete, or biased information, and it will churn out flawed, incomplete, and biased predictions. It’s the classic "garbage in, garbage out" problem, but with much higher stakes.
High-quality data ensures your models learn from a true picture of reality, which leads to better accuracy and outcomes you can actually trust. A solid data quality framework isn't just a nice-to-have for AI; it's a non-negotiable prerequisite for any organization that’s serious about getting real value from its machine learning investments.
Building a data quality framework is a critical undertaking, but it’s also a complex and resource-heavy one. NineArchs brings the specialized expertise and proven roadmaps to get you there faster. By partnering with a US-based outsourcing firm, you get immediate access to top-tier data governance and engineering talent without the long and expensive process of building a team from scratch. Let us build your data foundation, so you can focus on running your business.
To talk about how our dedicated team can build and implement your data quality framework, call us at (310) 800-1398 / (949) 861-1804 or email us at [email protected].



